
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- ICCV 2021
- 논문
- linux
- 논문리뷰
- 융합연구
- Paper
- Neural Radiance Field
- NERF
- pytorch
- 2022
- CVPR2023
- 논문 리뷰
- Deep Learning
- Semantic Segmentation
- panoptic segmentation
- docker
- Python
- GAN
- 딥러닝
- 파이토치
- 리눅스
- ICCV
- panoptic nerf
- paper review
- Vae
- NeRF paper
- IROS
- CVPR
- Computer Vision
- 경희대
- Today
- Total
윤제로의 제로베이스
VAE code review 본문
https://github.com/AntixK/PyTorch-VAE
GitHub - AntixK/PyTorch-VAE: A Collection of Variational Autoencoders (VAE) in PyTorch.
A Collection of Variational Autoencoders (VAE) in PyTorch. - GitHub - AntixK/PyTorch-VAE: A Collection of Variational Autoencoders (VAE) in PyTorch.
github.com
Base line

VAE 모델을 만들기 위한 가장 Base line은 다음과 같다.
위 github에 공유된 코드의 경우 다양한 VAE 모델들을 하나의 framework으로 훈련하고 사용할 수 있도록 되어 있기 때문에 VAE의 기본 틀이 짜여져 있다.
forward와 loss_function의 경우 다른 model들도 general하게 사용하는 부분이지만 그 외의 부분들은 vae에서 사용하는 부분이다.
Vanilla VAE
github에 다양한 VAE가 있지만 그 중에 가장 Basic 한 Vanilla VAE를 훑어볼 것이다.


여기서 hidden_dim의 경우 encoder와 decoder에 들어가는 layer들의 channel dim을 의미한다.
vanilla VAE의 경우 hidden_dims = [32, 64, 128, 256, 512]가 되므로 encoder의 output channel dim이 차례대로 32, 64, 128, 256, 512 가 된다.
더불어 Encoder와 Decoder 모두 Conv2d layer로 구성되게 된다.
Conv2d parameter가 kernel_size = 3, stricde = 2, padding = 1이므로 아래의 output size 수식에 따라 하나의 layer를 지날 때 마다 가로, 세로가 각각 절반씩 줄어 이미지의 크기는 1/4씩 압축되게 된다.

즉 가장 먼저 들어가는 이미지의 사이즈가 3 * 64 * 64 일 때 (이미지 크기가 64*64, RGB 3 channel) 5개의 layer를 지날 때 마다
3 * 64 * 64 → 32* 32 * 32 → 64 * 16 * 16 → 128 * 8 * 8 → 256 * 4 * 4 → 512 * 2 * 2 와 같은 output이 나오게 된다,
그리고 가장 마지막으로 fc_mu와 fc_var linear를 지나면서 우리가 원하는 latent_dim사이즈의 data distribution의 mean과 var를 얻게 된다.


앞서 Encoder를 만든 방식과 똑같이 Decoder를 만들어 준다.
이번에는 Conv2d layer가 아닌 ConvTranspose2d를 사용해서 가로 세로 길이를 2배씩 늘리고 channel수를 절반씩 줄여나가 Encoder 모델과 정반대의 process로 만든다.
이후 final_layer를 통해서 output channel로 3 channel을 만들도록 바꾸어주고 image size도 원래 size와 동일하게 복구한다.

fc_mu와 fc_var을 encoder와 함께 붙여서 한 번에 mu와 log_var를 return 받을 수 있도록 한다.
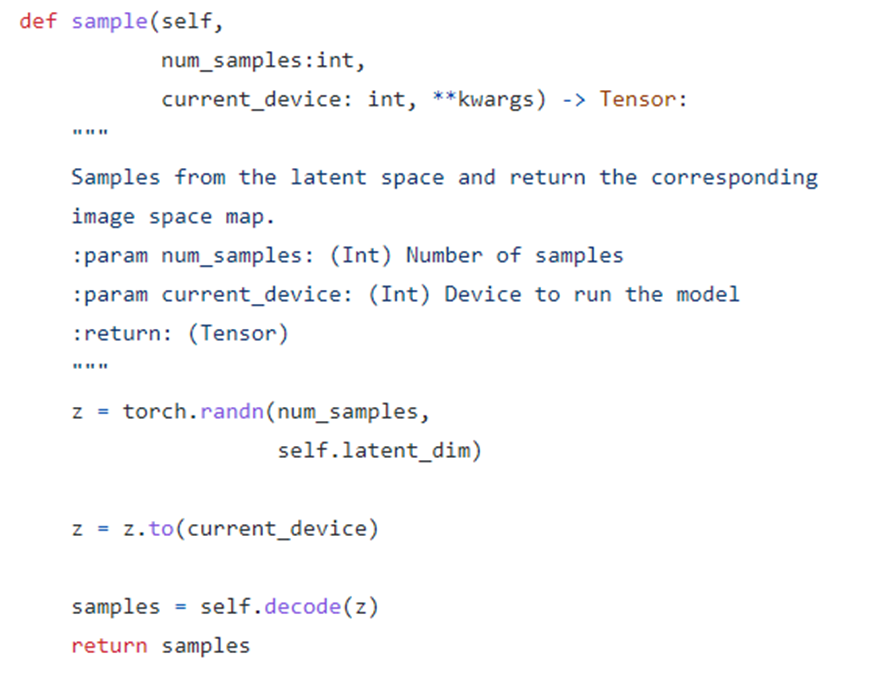
Sample function의 경우, VAE는 generative model이기 때문에 latent space에서 뽑은 값으로 image를 생성해낼 수 있어야한다. Vanilla VAE는 normal distribute에 근사하도록 training 되기 때문에 normal distrbution에서 samping한 난수를 decode에 넣어서 결과를 얻는다.

reparameterize function의 경우 auto encoder가 아닌 VAE가 갖게되는 특징 중 하나이다. 기존의 Auto Encoder에서는 그저 std와 mu를 통해서 random sampling을 하였지만 여기서는 random noise에 std를 곱하고 mu를 더하는 식으로 만들어 backpropagation이 가능하도록 만들었다.



위와 같은 식이 논문에서 구현된 loss function이다. 이를 code level로 구현하기 위해서 적분식이 아닌 sum으로 계산하여 loss를 만들었다.

Experiment
이후 VAExperiment를 통해 training과 validation을 할 수 있는 step을 정의한다.






Run
이 코드는 pytorch lightning을 사용하여서 model의 TensorBoardLogger를 훨씬 보기 쉽게 만들었다.



Result
위 코드를 Cellab Dataset을 바탕으로 직접 Training을 돌려보았다. 아래는 그 결과이다.
Sampling


Reconstruction


epoch 1일때에도 사람의 이목구비는 보이는 편이지만 epoch 100에 비하면 훨씬 흐린 편이다.
하지만 여기서 보이는 결과를 비추어 볼 때에는 사람의 이목구비 이외의 머리카락이나 배경은 모두 noisy하게 blur처리 된 것을 볼 수 있다. 이는 GAN과 VAE가 보이는 확연한 차이 중 하나이다.
비교적 선명한 사진을 보여주는 GAN과 달리 VAE의 경우에는 전체적으로 blur한 이미지를 보여주는 것이 특징이다. 이 때문에 이러한 blur한 이미지를 보이지 않으려는 것이 VAE의 가장 화두되는 개선 방안 중 하나이다.
'Self Paper-Seminar > VAE' 카테고리의 다른 글
| VDVAE: Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images (0) | 2022.11.16 |
|---|---|
| Soft-Intro VAE: Analyzing and Improving the Introspective Variational Autoencoder (0) | 2022.11.02 |
| Intro-VAE (0) | 2022.10.25 |
| InfoVAE: Information Maximizing Variational Autoencoders (0) | 2022.10.19 |
| VQ-VAE (Neural Discrete Representation Learning) (0) | 2022.10.12 |



