
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 파이토치
- Python
- ICCV
- Computer Vision
- 논문리뷰
- 경희대
- 논문 리뷰
- 리눅스
- Neural Radiance Field
- 논문
- ICCV 2021
- Vae
- Semantic Segmentation
- pytorch
- CVPR2023
- 융합연구
- Paper
- linux
- 딥러닝
- panoptic nerf
- paper review
- NeRF paper
- 2022
- docker
- CVPR
- Deep Learning
- GAN
- IROS
- NERF
- panoptic segmentation
- Today
- Total
윤제로의 제로베이스
비선형 활성화 함수(Activation function) 본문
06. 비선형 활성화 함수(Activation function)
비선형 활성화 함수(Activation function)는 입력을 받아 수학적 변환을 수행하고 출력을 생성하는 함수입니다. 앞서 배운 시그모이드 함수나 소프트맥스 함수는 대 ...
wikidocs.net
비선형 활성화 함수(Activation function)는 입력을 받아 수학적 변환을 수행하고 출력을 생성하는 함수이다.
1. 활성화 함수의 특징 - 비선형 함수(Nonlinear function)
활성화 함수의 특징은 비선형 함수여야한다는 점이다.
인공 신경망의 능력을 높이기 위해서는 은닉층을 계속 추가해야한다.
하지만 만약 활성화 함수를 선형 함수로 사용하게 되면 은닉층을 쌓을 수가 없다.
즉, 선형 함수로는 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이를 줄 수 없다.
물론 가중치가 새로 생긴다는 점에서 의미는 분명 있다.
이와 같이 선형 함수를 사용한 층을 활성화 함수를 사용하는 은닉층과 구분하기 위해서 선형층(Linear layer)이나 투사층(projection layer) 등의 다른 표현을 사용하여 표현하기도 한다.
활성화 함수를 사용하는 일반적인 은닉층을 선형층과 대비되는 표현을 사용하면 비선형층(nonlinear layer)이다.
2. 시그모이드 함수(Sigmoid function)와 기울기 소실

위 그림에서 인공 신경망의 학습 과정은 입력에 대한 순전파(forward propagation) 연산을 한다.
그리고 순전파 연산을 통해 나온 예측값과 실제값의 오차를 손실 함수(loss function)을 통해 계산하고, 이 손실(loss)을 미분을 통해서 기울기(gradient)를 구하고, 이를 통해 역전파(backpropagation)를 수행한다.
# 시그모이드 함수 그래프를 그리는 코드
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()

주황색 부분은 기울기를 계산하면 0에 가까운 아주 작은 값이 나오게 된다.
그런데 역전파 과정에서 0에 가까운 아주 작은 기울기가 곱해지게 되면, 앞단에는 기울기가 잘 전달되지 않게 된다.
이러한 현상을 기울기 소실(Vanishing Gradient) 문제라고 한다.
시그모이드 함수를 사용하는 은닉층의 개수가 다수가 될 경우에는 0에 가까운 기울기가 계속 곱해지면 앞단에서는 기울기를 거의 전파받을 수 없게 된다.
다시 말해 매개변수 W가 업데이트 되지 않아 학습이 되지 않는다.

3. 하이퍼볼릭탄젠트 함수(Hyperbolic tangent function)
x = np.arange(-5.0, 5.0, 0.1) # -5.0부터 5.0까지 0.1 간격 생성
y = np.tanh(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,-1.0], ':')
plt.axhline(y=0, color='orange', linestyle='--')
plt.title('Tanh Function')
plt.show()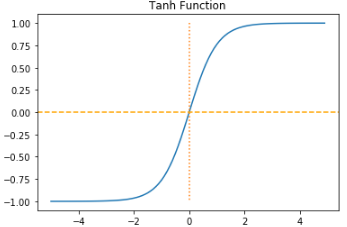
하이퍼볼릭탄젠트 함수도 -1과 1에 가까운 출력값을 출력할 때, 시그모이드 함수와 같은 문제가 발생한다.
그러나 하이퍼볼릭탄젠트 함수의 경우에는 시그모이드 함수와는 달리 0을 중심으로 하고 있는데, 이때문에 시그모이드 함수와 비교하면 반환값의 변화폭이 더 크다.
그래서 시그모이드 함수보다 기울기 소실 증상이 적은 편이다.
그래서 은닉층에서 시그모이드 함수보다 많이 사용된다.
4. 렐루 함수(ReLU)
def relu(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Relu Function')
plt.show()
렐루 함수는 음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환한다.
렐루 함수는 특정 양수값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동한다.
뿐만 아니라, 렐루 함수는 시그모이드 함수와 하이퍼볼릭탄젠트 함수와 같이 어떤 연산이 필요한 것이 아니라 단순 임계값이므로 연산 속도가 빠르다.
하지만 입력값이 음수면 기울기가 0이된다는 문제점이 있다.
그리고 이 뉴런은 다시 회생하는 것이 매우 어렵다.
이 문제를 죽은 렐루(dying ReLU)라고 한다.
5. 리키 렐루(Leaky ReLU)
죽은 렐루를 보완하기 위해 등장한 것이 Leaky ReLU이다.
Leaky ReLU는 입력값이 음수일 경우에 0이 아니라 0.001과 같은 매우 작은 수를 반환하도록 되어있다.
def leaky_relu(x):
return np.maximum(a*x, x)
x = np.arange(-5.0, 5.0, 0.1)
y = leaky_relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Leaky ReLU Function')
plt.show()
입력값이 음수더라도 기울기가 0이 되지 않으면 ReLU는 죽지 않는다.
6. 소프트맥스 함수(Softmax function)
x = np.arange(-5.0, 5.0, 0.1) # -5.0부터 5.0까지 0.1 간격 생성
y = np.exp(x) / np.sum(np.exp(x))
plt.plot(x, y)
plt.title('Softmax Function')
plt.show()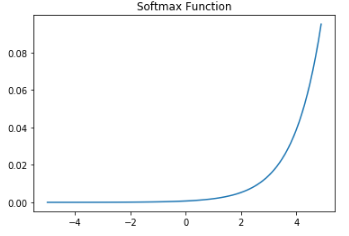
은닉층에서 ReLU 함수들을 사용하는 것이 일반적이지만 그렇다고 시그모이드 함수나 소프트맥스 함수가 사용되지 않는다는 의미는 아니다.
소프트맥스 함수는 시그모이드 함수처럼 출력층의 뉴런에서 주로 사용되는데, 시그모이드 함수가 두가지 선택지 중 하나를 고르는 이진 분류 문제에 사용된다면, 세 가지 이상의 선택지 중 하나를 고르는 다중 클래스 분류 문제에 주로 사용된다.
7. 출력층의 활성화 함수와 오차 함수의 관계
| 문제 | 활성화 함수 | 비용 함수 |
| 이진 분류 | 시그모이드 | nn.BCELoss() |
| 다중 클래스 분류 | 소프트맥스 | nn.CrossEntropyLoss() |
| 회귀 | 없음 | MSE |
- 시그모이드 함수의 또 다른 문제점은 원점 중심이 아니라는 점이다. 따라서, 평균이 0이 아니라 0.5이며, 시그모이드 함수는 항상 양수를 출력하기 때문에 출력의 가중치 합이 입력의 가중치 합보다 커질 가능성이 높다. 이것을 편향 이동(bias shift)이라고 하며, 이러한 이유로 각 레이어를 지날 때마다 분산이 계속 커져 가장 높은 레이어에서는 활성화 함수의 출력이 0이나 1로 수렴하게 되어 기울기 소실 문제가 일어날 수 있다.
- 하이퍼볼릭탄젠트 함수는 원점 중심(zero-centered)이기 때문에, 시그모이드와 달리 편향 이동은 일어나지 않는다. 하지만, 하이퍼볼릭탄젠트 함수 또한 입력의 절대값이 클 경우 -1이나 1로 수렴하게 되는데 시그모이드 함수와 마찬가지로 이떄 기울기가 완만해지므로 기울기 소실 문제가 일어날 수 있다.
'Background > Pytorch 기초' 카테고리의 다른 글
| 기울기 소실(Gradient Vanishing)과 폭주(Exploding) (0) | 2022.01.19 |
|---|---|
| 과적합(Overfitting)을 막는 방법들 (0) | 2022.01.17 |
| 역전파(Backpropagation) (0) | 2022.01.17 |
| 퍼셉트론(Perceptron) (0) | 2022.01.16 |
| 머신 러닝 용어 이해하기 (0) | 2022.01.16 |


