
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Python
- 딥러닝
- NeRF paper
- Paper
- 파이토치
- Semantic Segmentation
- 논문리뷰
- ICCV 2021
- Computer Vision
- Vae
- Neural Radiance Field
- docker
- 융합연구
- ICCV
- Deep Learning
- 논문 리뷰
- GAN
- NERF
- 리눅스
- CVPR2023
- 2022
- CVPR
- 경희대
- linux
- 논문
- pytorch
- panoptic nerf
- IROS
- panoptic segmentation
- paper review
- Today
- Total
윤제로의 제로베이스
pixelNeRF: Neural Radiance Fields from One or Few Images 본문
pixelNeRF: Neural Radiance Fields from One or Few Images
윤_제로 2023. 6. 10. 02:42https://github.com/sxyu/pixel-nerf
GitHub - sxyu/pixel-nerf: PixelNeRF Official Repository
PixelNeRF Official Repository. Contribute to sxyu/pixel-nerf development by creating an account on GitHub.
github.com
http://arxiv.org/abs/2012.02190
pixelNeRF: Neural Radiance Fields from One or Few Images
We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene in
arxiv.org
오늘 볼 논문은 pixelNeRF로 기존의 NeRF들과는 다르게 1개 혹은 적은 양의 image dataset만으로도 학습이 가능한 learning framework이다.
Introduction
기존 NeRF의 한계
geometry consistency만으로 optimization하는 방법이기 떄문에 scene마다 knowledge가 공유되지 않고 각각의 scene 마다 개별적으로 모델 학습을 해야한다.
이로 인해서 학습 시간이 굉장히 오래 걸리며 sparse한 image dataset으로는 학습이 어렵다.
그래서 이를 보완하기 위해서 이미지와 이미지에서 추출되는 ray들만을 가지고 학습했던 NeRF와는 달리 pixelNeRF는 픽셀마다 이미지의 feature를 입력으로 가져간다.
간략하게 정리하면 아래와 같이 동작한다고 생각하면 될 것 같다.
- input image에서 fully convolution image feature grid를 계산하고 NeRF의 input image를 조절
- 각각의 query point x와 viewing direction d에 대해서 projection을 하고 bilinear interpolation을 통해 image에 각각의 feature 를 주입한다.

Image-conditioned NeRF
모델의 구성은 다음과 같다.
1. Fully-convolutional image encoder E(input image를 pixel-aligned feature grid로 encoding)
2. NeRF network f
이를 위해서 input view의 camera space에서 모델링을 한다.
Single-Image pixelNeRF
일단 좌표계를 input image에 대한 view space로 고정하고 이 위치에서 camera ray를 지정한다.
scene에 대한 Image I를 Encoder로 넣어 feature volume W를 추ㅜㅊㄹ한다. 그 후 camera ray의 point x를 image 평면으로 projection한 후에 대응하는 image feautre를 찾는다. pixel 단위 features사이에 bilinear interpolate를 통해서 feature vector를 추출한다.
Query view direction
few-shot view에서의 query view direction은 NeRF에서 특정 image feature의 중요성을 결정하는데 유용하다.
query view direction이 input view 방향과 유사하다면, model은 input에 더 의존하게 된다. 그렇지 않다면 모델은 학습된 prior에 집중할 것이다.
multi-view에서는 view directions는 다른 view와의 관련성에 대한 근거가 될 수 있다.
위와같은 여러 이유로 view를 입력으로 주게 된다.
Incorporating Multiple Views
multiple input view라고 할 때 우린 relative camera pose만을 알 수 있다고 가정하낟.
i번째 input image를 I^i라고 하자.
이와 관련된 camera transform from world to view 를 P라고 한다.

새로운 target camera ray에 대해서 query point x와 view direction d를 각 input view i의 좌표계로 transform한다.

output인 density와 rgb값을 얻기 위해서 각각의 view 좌표를 feature와 독립적으로 처리한다.
inputs을 NeRF의 initial layer에 넣어 intermediate vectors를 얻는다.
intermediate vectors는 average pooling operator와 합쳐진 후 final layer로 들어간 후 density와 rgb를 예측하게 된다.
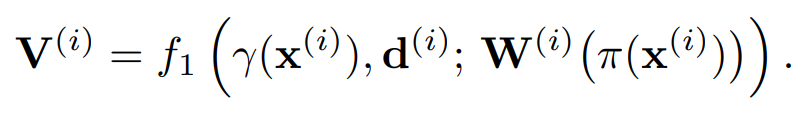
Limitation
- 속도가 굉장히 느리고, input view가 늘어날 수록 시간은 선형적으로 증가하낟.
- 사실적인 mesh 변환은 어렵다
- scale를 자체적으로 제한했다. 이게 어렵다,,
- large-scale로 넘어가면 bottle-neck으로 인해서 성능이 좋아지긴 쉽지 않다.
'Self Paper-Seminar > NeRF' 카테고리의 다른 글
| Depth-supervised NeRF: Fewer Views and Faster Training for Free. (0) | 2023.06.10 |
|---|---|
| Unsupervised Continual Semantic Adaptation through Neural Rendering (2) | 2023.06.10 |
| Instance Neural Radiance Field (0) | 2023.05.01 |
| Panoptic NeRF: 3D-to-2D Label Transfer for Panoptic Urban Scene Segmentation (0) | 2023.05.01 |
| Panoptic NeRF (0) | 2023.04.26 |



