
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 경희대
- GAN
- ICCV
- Paper
- 논문리뷰
- Neural Radiance Field
- 논문 리뷰
- panoptic segmentation
- 딥러닝
- paper review
- 논문
- ICCV 2021
- Semantic Segmentation
- IROS
- Deep Learning
- CVPR
- pytorch
- NERF
- 2022
- Python
- docker
- 파이토치
- CVPR2023
- panoptic nerf
- 융합연구
- 리눅스
- linux
- NeRF paper
- Vae
- Computer Vision
- Today
- Total
윤제로의 제로베이스
Depth-supervised NeRF: Fewer Views and Faster Training for Free. 본문
Depth-supervised NeRF: Fewer Views and Faster Training for Free.
윤_제로 2023. 6. 10. 04:51https://arxiv.org/pdf/2107.02791.pdf
https://github.com/dunbar12138/DSNeRF
GitHub - dunbar12138/DSNeRF: Code release for DS-NeRF (Depth-supervised Neural Radiance Fields)
Code release for DS-NeRF (Depth-supervised Neural Radiance Fields) - GitHub - dunbar12138/DSNeRF: Code release for DS-NeRF (Depth-supervised Neural Radiance Fields)
github.com
기존의 pixelNeRF, MVSNeRF등 다양한 NeRF 논문들이 1장 혹은 적은 양의 image dataset으로 학습이 가능한 NeRF를 위해 연구를 해왔다.
DS-NeRF에서는 Point CLoud 정보를 추가로 활용한다. 이때 Point Cloud의 경우 Depth Camera로 추출한 것이 아닌 COLMAP을 사용하여 3D Point cloud를 추정하여 사용하였다.
Overall

Loss Function
DS-NeRF의 Loss function은 Color Supervision Loss와 Depth Supervision Loss로 이루어져 있다.

Depth Supervision Loss
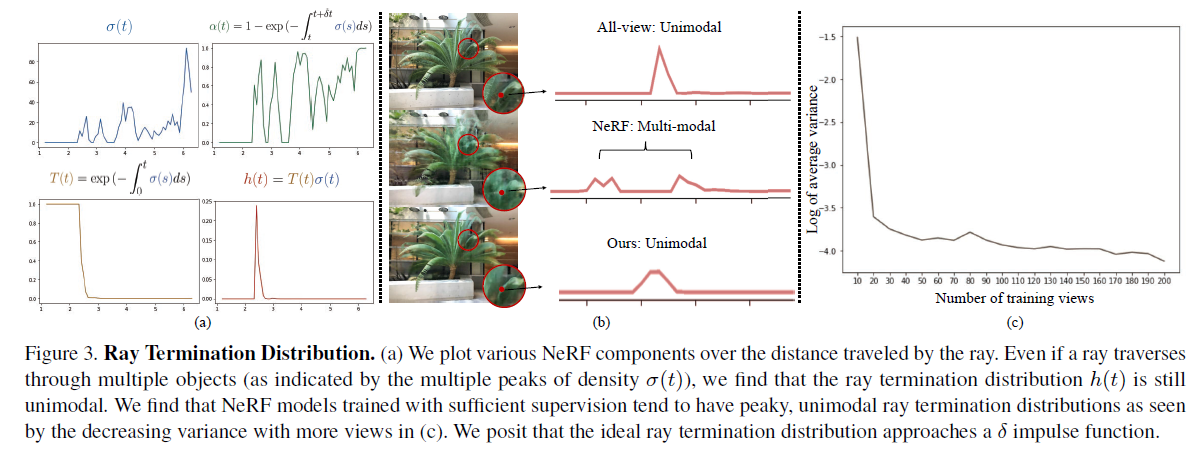
위 그림 (b)의 빨간 지점으로 ray를 직접 그려보면 Ray 위의 여러 Object로 인해 깊이의 voxel에 대한 density가 (a)-1처럼 그려진다. Rendering 공식을 통해 h(t)가 계산이 되고 (a)-4 처럼 그려지게 된다.
저자는 h(t) 값을 더 실제 depth와 비슷한 분포로 만들려고 했다.
실제로 DS-NeRF는 (b)-2의 Multi-modal 분포를 (b)-3로 표현하기 위해서 3D point cloud 정보로 Depth Supervision Loss를 설계하였다.

j번째 이미지의 i번째 3D keypoint들과 ray sampling 깊이 t가 변수로 주어진다.
왼쪽의 기댓값은 Surface와 가장 가까운 깊이 D와 sampling한 깊이 t 간의 차이에 대한 distribution delta가 inference h 함수에 대한 dsitribution과 유사하게 만들고자 함을 의미한다.
이는 결국 colmap에서의 depth D에 대한 distribution과 inference h함수에 대한 KL Divergence를 최소화하도록 된다.
즉 어떠한 3D Point에 대해서 서로 다른 view direction에서의 ray를 그렸다고 생각하자.
임의의 1개의 ray에서의 estimated depth D와 Sampling depth t 간의 차이에 관한 distribution이 COLMAP으로 구한 depth D에 대한 Normal Distribution으로 표현 가능하다는 것이다.
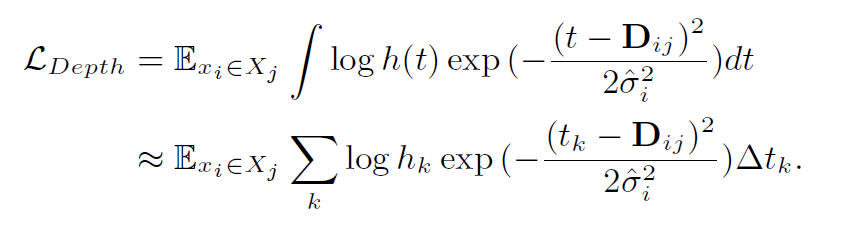
결국 위와 같은 형태로 Loss 값이 정의된다.


실제로 실험을 진행하였을 때 3-view 보다는 6-view 이상에서 성능이 더 잘 나오는 것을 볼 수 있다.
더불어서 target domain에 큰 영향을 받지 않고 inference하는 것을 볼 수 있다.
'Self Paper-Seminar > NeRF' 카테고리의 다른 글
| RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs (0) | 2023.06.21 |
|---|---|
| Mip-NeRF: Multiscale Representation for Anti-Aliasing Neural Radiance Fields (0) | 2023.06.21 |
| Unsupervised Continual Semantic Adaptation through Neural Rendering (2) | 2023.06.10 |
| pixelNeRF: Neural Radiance Fields from One or Few Images (1) | 2023.06.10 |
| Instance Neural Radiance Field (0) | 2023.05.01 |



