
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 경희대
- 파이토치
- 2022
- NeRF paper
- 딥러닝
- Python
- Neural Radiance Field
- 논문 리뷰
- 융합연구
- pytorch
- 리눅스
- panoptic segmentation
- panoptic nerf
- GAN
- Vae
- 논문리뷰
- ICCV 2021
- CVPR
- Paper
- IROS
- paper review
- CVPR2023
- ICCV
- Deep Learning
- 논문
- docker
- linux
- Semantic Segmentation
- Computer Vision
- NERF
- Today
- Total
윤제로의 제로베이스
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs 본문
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
윤_제로 2023. 6. 21. 17:56https://m-niemeyer.github.io/regnerf
RegNeRF
NeRF optimizes the reconstruction loss for a given set of input images (blue cameras). For sparse inputs, however, this leads to degenerate solutions. In this work, we propose to sample unobserved views (red cameras) and regularize the geometry and appeara
m-niemeyer.github.io

NeRF에 sparse한 input을 넣을 경우에 위처럼 아티팩트처럼 제대로 이미지 렌더링이 되지 않는다.
이를 해결하기 위해서 RegNeRF에서는 novel view에 대한 geometry와 appearance를 regularize하고 ray sample space를 학습 중에 해제하여 해결하였다.
Introduction
이 논문 이전에 나온 few image를 input으로 주었을 때 보이지 않은 장면을 만들어 주던 NeRF로 Pixel NeRF가 있었다. Pixel NeRF의 한계점은 일단 학습을 하기 위해서는 camera pose를 알고 있는 대규모 이미지 데이터를 pre-train 해야했다. 더불어 학습시에 사용했던 데이터셋과 테스트에 사용하는 데이터의 domain gap이 있다면 제대로 성능을 내지 못한다는 한계도 갖고 있었다.
contribution
- unobserved viewpoints로 부터 렌더링 된 depth map을 위해 patch-baed regularizer으로 scene geometry 개선
- 렌더링된 patch의 log-likelihood를 maximaize하여 unobserved viewpoints에서 예측되는 색을 regularize.
- scene content를 작은 범위 내에서 sampling
Related Work
일단 RegNeRF는 mip-NeRF를 기반으로 하는 모델이다.
이전의 Sparse input novel view synthesis 기법은
- PixelNeRF : CNN feature를 추출
- MVSNeRF : 이미지 와핑을 통한 3D cost volume
두 모델 모두 pre-training을 필요로 하는 모델이다. 하지만 실제로는 pre-training을 할 데이터가 항상 있는 것이 아니기 때문에 최대한 pre-training을 피하는 방식으로 시도하였다.
Method

1) Patch-based Regularization
sparse scene에 대해서 NeRF는 항상 overfitting 문제를 일으킨다. 이를 해결하기 위해서 Regularize를 한다.
간단히 말하면 unobserved지만 관련이 있는 view point를 정의하고 이 view point로부터 랜덤으로 patch를 렌더링한다. 이러한 패치들을 regularize하는 방향으로
Unobserved Viewpoint Selection
가장먼저 unobserved camera poses들의 sample space를 정의한다. 일단 알고 있는 target poses들에 대해 아래와 같다고 할 때

target poses를 기반으로 가능한 camera location을 지정한다.

더불어 가능한 rotation도 지정한다.

rotation을 구하기 위해서는 일단 모든 카메들이 focus on object라고 가정한다.
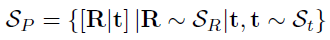
Geometry Regularization
실제 object는 평평한 표면이 대부분이다. 그래서 unobserved viewpoints에서 depth smoothness를 위해서 prior을 모델에 적용시켰다.


Color Regularization


Total Loss

2) Sample Space Annealing
sparse input일 때 sampling space를 최적화 할 때 annealing하여 초기 발산 문제를 해결한다.
t_n, t_f를 camera의 near과 far이라고 하고 t_m을 그 중앙이라 할 때

이와 같은 annealing을 input pose와 sampled unobserved viewpoint에 적용하여 학습의 발산을 막도록 하였다.



