
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- CVPR2023
- Paper
- 딥러닝
- 논문
- 파이토치
- 리눅스
- NeRF paper
- paper review
- panoptic nerf
- linux
- Vae
- pytorch
- 논문리뷰
- ICCV 2021
- IROS
- Neural Radiance Field
- Python
- 2022
- Deep Learning
- NERF
- Computer Vision
- GAN
- 논문 리뷰
- CVPR
- docker
- ICCV
- 융합연구
- panoptic segmentation
- 경희대
- Semantic Segmentation
- Today
- Total
윤제로의 제로베이스
Point-NeRF: Point-based Neural(CVPR2022) 본문
요즘 NeRF에 대해 공부하고 있다.
2020년에 처음 등장한 모델인데 3D vision과 관련이 많은 모델이다 보니 굉장히 핫하게 논문이 많이 올라오고 있는 것 같다.
그래서 GAN을 공부할 때에 비해 상당히 최근 논문들이 많다.
오늘은 그 중에 CVPR 2022 Oral에 올랐던 논문인 Point-NeRF에 대해 정리를 해볼까 한다.
https://xharlie.github.io/projects/project_sites/pointnerf/
Point-NeRF: Point-based Neural Radiance Fields
Bibtex @article{xu2022point, title={Point-NeRF: Point-based Neural Radiance Fields}, author={Xu, Qiangeng and Xu, Zexiang and Philip, Julien and Bi, Sai and Shu, Zhixin and Sunkavalli, Kalyan and Neumann, Ulrich}, journal={arXiv preprint arXiv:2201.08845},
xharlie.github.io
Introduction
NeRF와 그 이후 후속의 NeRF의 경우 대부분 ray marching과 global MLP를 사용하여 radiance field를 reconstruction하였다.
이 때 NeRF의 경우 scene마다 fitting을 진행했기 때문에 reconstruction하는 시간이 굉장히 오래 걸렸으며 sampling을 진행할 때에도 필연적으로 불필요한 sampling을 하였다.
이러한 점이 NeRF의 속도를 저하시키는 가장 큰 요인이 되었다.
그래서 이러한 단점들을 보완하기 위해서 나온 모델이 바로 Point-NeRF이다.
Point NeRF의 가장 대표적인 특징 3가지를 아래와 같다.
- Uses 3D neural points to model continuous volumetric radiance fields
- Effectively initialized via a feed-forward deep neural network, pre-trained across scenes.
- Leverage classical point clouds to avoid ray sampling in the empty scene space
Related work
1) MVSNet
여기서 MVS는 Multi-View Synthetic 이라고 생각하면 된다.
3장의 사진을 input으로 넣고 이에 대한 depth map을계산해주는 모델이라 생각하면 될 것 같다.

2) COLMAP
COLMAP은 사진을 input으로 받았을 때에 SHIT을 사용하여 keypoint를 찾고 매칭하여 epipolar geometry 좌표에 넣어 삼각법을 통해 3D 좌표를 예측하고 point cloud로 reconstruction해주는 역할을 한다.
point-nerf의 경우 point cloud의 geometry를 기반으로 작동하기 때문에 model 자체적으로 있는 point cloud 생성기를 사용하여도 되지만 외부에서 만든 point cloud를 접목시켜서 사용할 수도 있다.
그 예시로 나왔던 tool이 colmap이다.

3. Point-NeRF Representation
1) Neural Point Generation
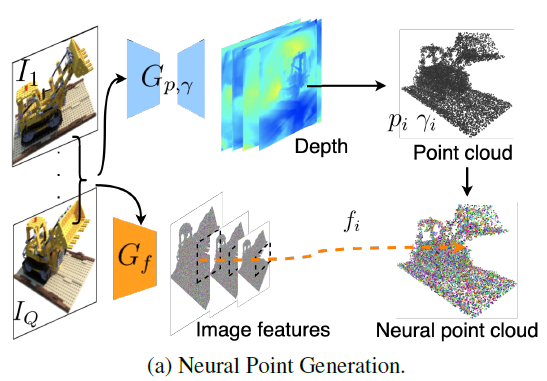
첫번째 G_p의 경우 이미지를 input으로 받았을 때 depth map을 추정하여 point cloud를 만든다.
이때 MVSNet을 기반으로 만들어진 G_p이기 때문에 depth map을 만들어낼 수 있다.
input으로는 이미지와 camera parameters가 들어가고 output으로는 point cloud (p)와 point confidence(gamma)가 나온다.
이때 point confidence란 point cloud에서 한 점이 surface일 확률을 나타낸 것이다.
그 다음 G_f는 vgg network기반의 feature vector extraction을 진행하는 부분이다.
여기서 2D CNN을 바탕으로 각 layer에 feature map을 얻을 수 있게 된다.
이 feature를 point에 mapping하여 구성하게 만든다.
2) Point Sampling feature extraction

이제 novel view에서의 image를 얻기 위해서 target view image에서 각각의 픽셀에 해당하는 ray를 통해 지나가는 point들을 계산하게 된다.
이때 point들의 좌표가 voxel 좌표로 나타나있어서 정확하게 그점을 지나는게 아니더라도 계산이 되는거지 않을까 싶다.
최초의 NeRF와는 달리 Neural point confidence값을 사용하기 때문에 Empty space에서의 불필요한 sampling을 피하여 속도를 개선하였다.
더불어 하나의 포인트만으로 계산을 하는 것이 아니라 주변의 point도 함께 계산하게 된다.
이에 대해 아래에서 더 자세히 다뤄보자.
3) Per-point processing

ray위의 점 x와 그 주변의 K개의 점 p_K를 함게 sampling하게 된다.
포인트 p_K와 mapping된 feature를 f_K라고 할 때 x와 p_K 사이의 상대적인 거리와 feature를 함께 계산하여 새로운 feature f_k,x를 만들어낸다.
새롭게 얻은 feature의 weighted sum을 통해 density와 radiance를 얻게 된다.
4) Compute View-dependent radiance regression

앞서 새롭게 얻은 feature 값들을 weighted sum하여 얻은 값과 position encoding을 한 direction vector를 통해서 view-dependent한 radiance를 계산한다.
weighted sum 공식은 다음과 같다.

5) Density Regression

새로운 feature f_k,x를 통해서 새로운 feature를 계산했던 것 처럼 이번에는 MLP를 통과하여 density 도출한다.
이후 각각의 density도 weighted sum하여 최종적으로 x에 대한 density를 계산한다.
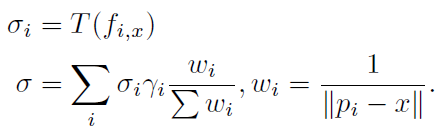
4. Point-NeRF Reconstruction
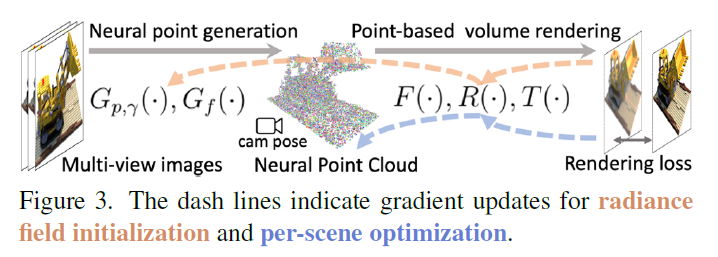
Point NeRF의 경우 NeRF와 달리 per-scene 마다 network 전체를 optimize하지 않는다.
pre-trained 모델로 전체적으로 학습을 시킨 후에 만들고자 하는 scene에 대해서 F, R,T에 대해 fine tuning하는 방식으로 모델을 학습시킨다.
그렇기 때문에 per-csene fitting 시간이 확 줄어들게 된다.

per-csene optimize를 할 때, point를 그대로 optimizing하는 것은 학습이 불안정하게 되고 중간중간 큰 구멍이 발생하게 된다.
그래서 이를 막고자 논문은 point pruning, growing을 진행한다.
Point pruning
Point pruning은 말 그대로 point를 줄여나가는 것이다.
point cloud를 생성하면 노이즈가 낄 수 밖에 없다.
이 때 발생하는 noise artifact를 줄이기 위해서 pruning을 진행한다.
여기서 pruning을 진행하는 기준은 confidence value 이다.
10k iteration마다 confidence value가 0.1을 넘지 못하면 point를 지운다.
또한 아래의 loss 값을 통해서 confidnece value자체가 0또는 1로 나타나지도록 양극화를 시도한다.

Point growing
ray 위의 점 중에가 가장 opacity가 높은 점을 찾는다.
혹시나 그 point가 아래의 수식을 만족하면 point를 grow한다.
growing하려는 point들은 모두 surface에서 가까운 점이면서도 다른 배우들과 친해지지 못한 것을 말한다.


